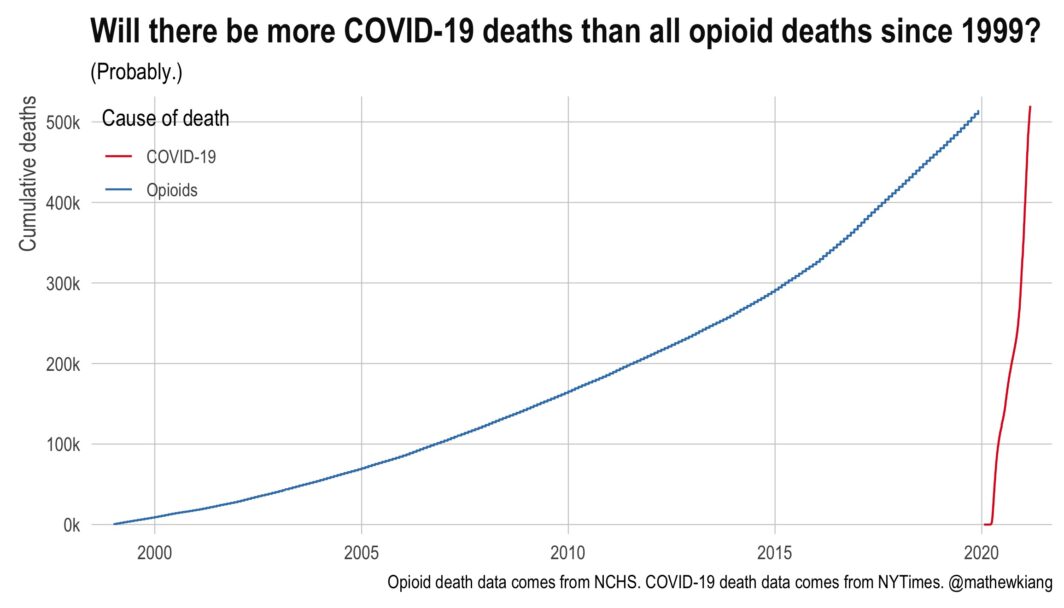
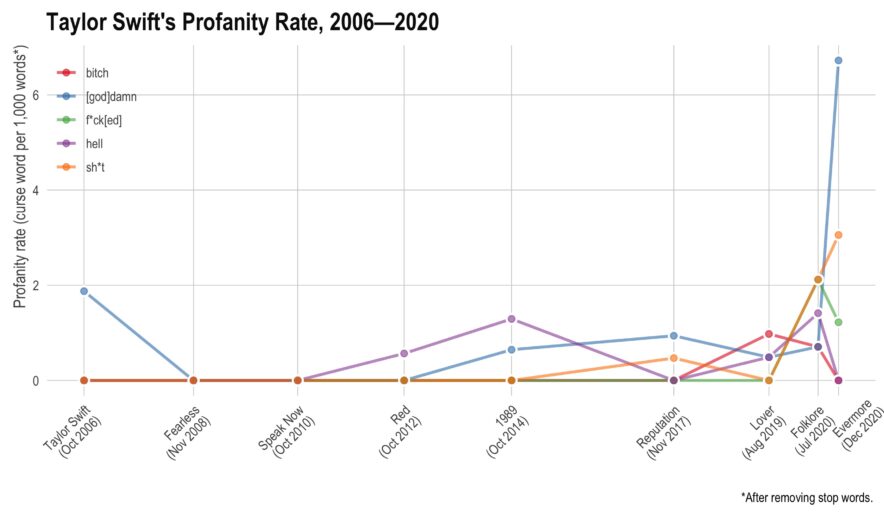
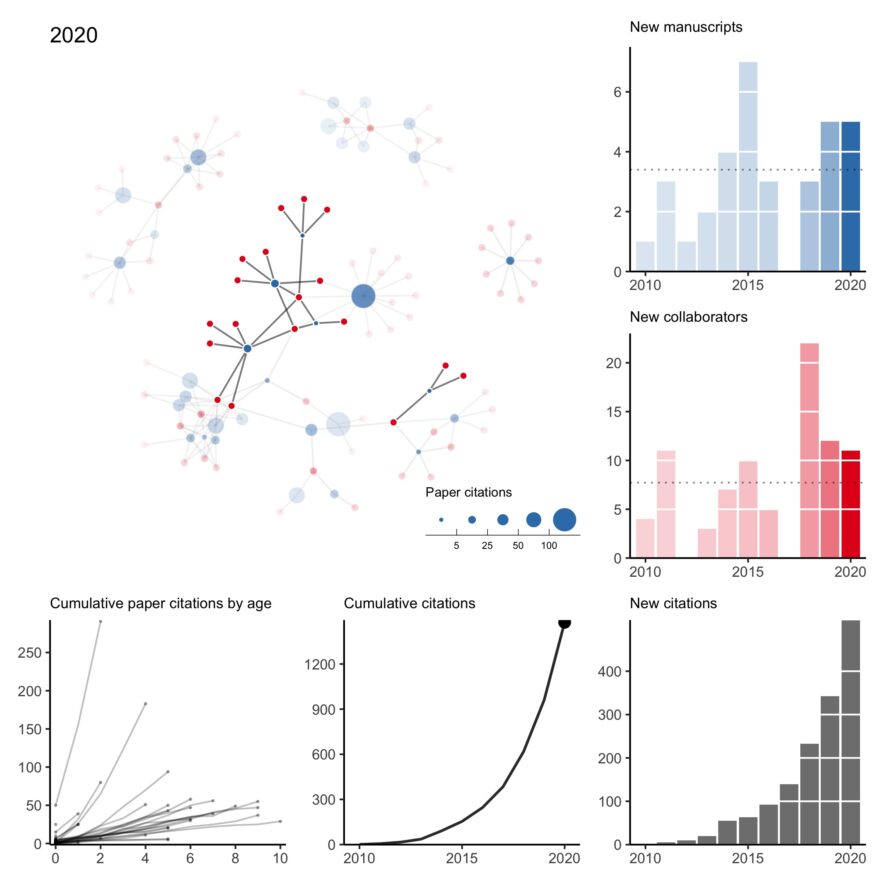
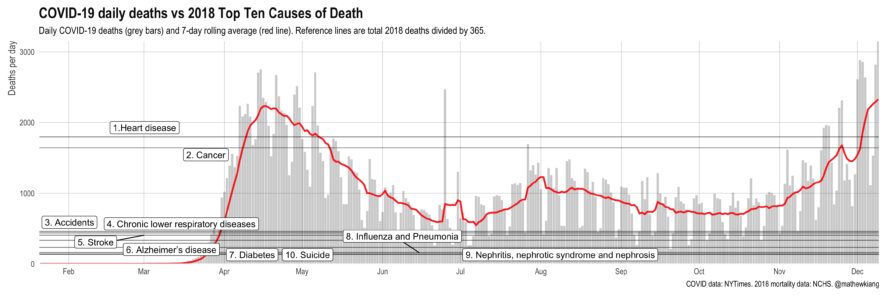
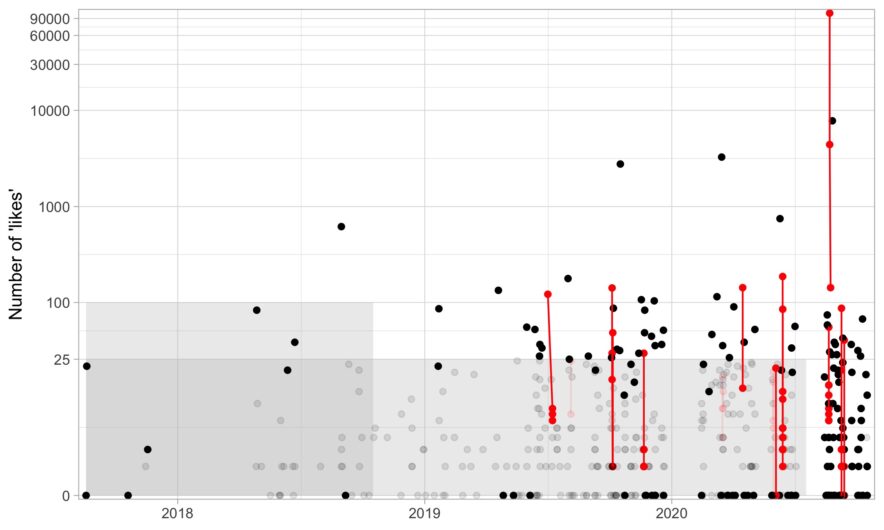
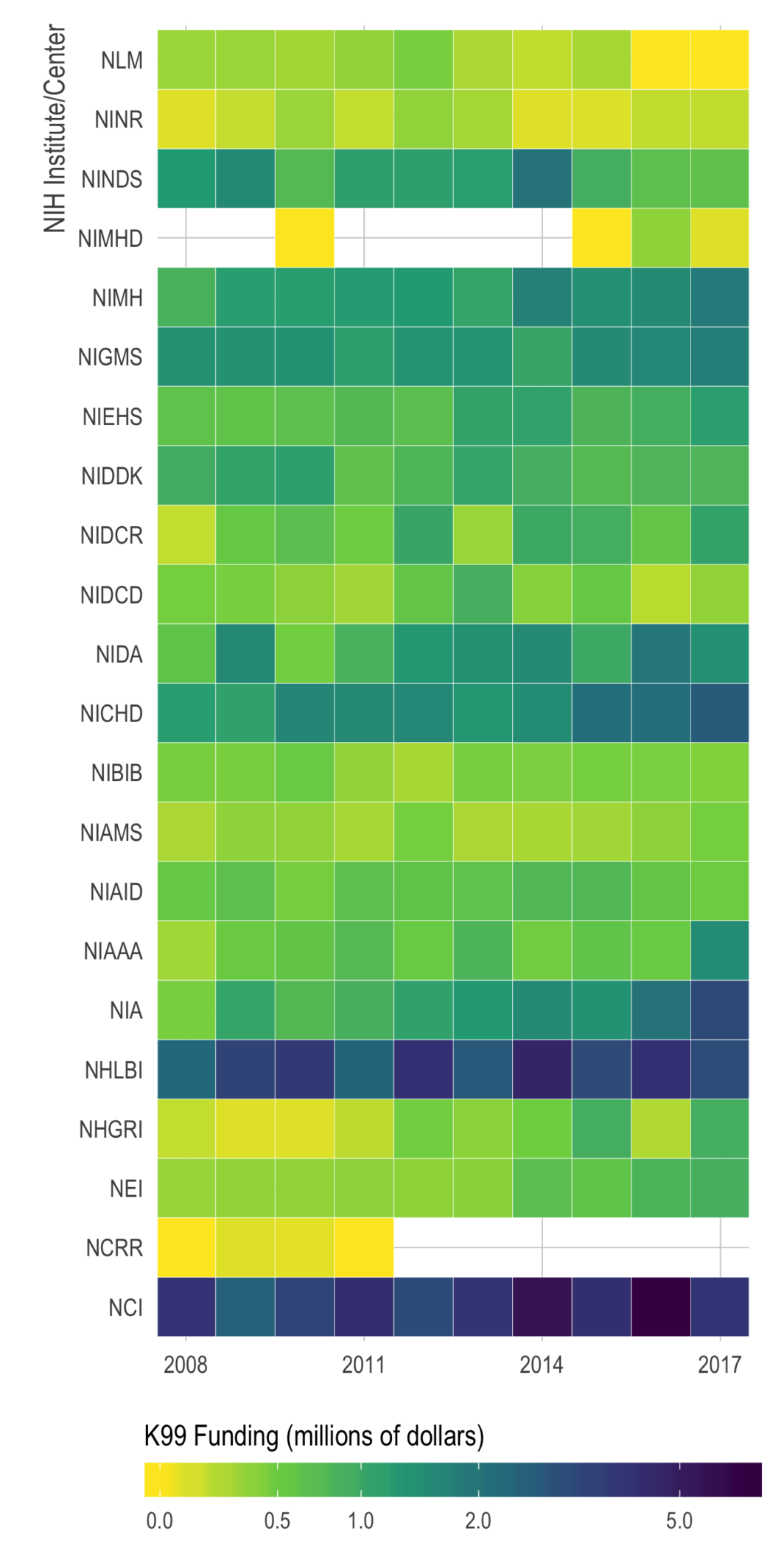
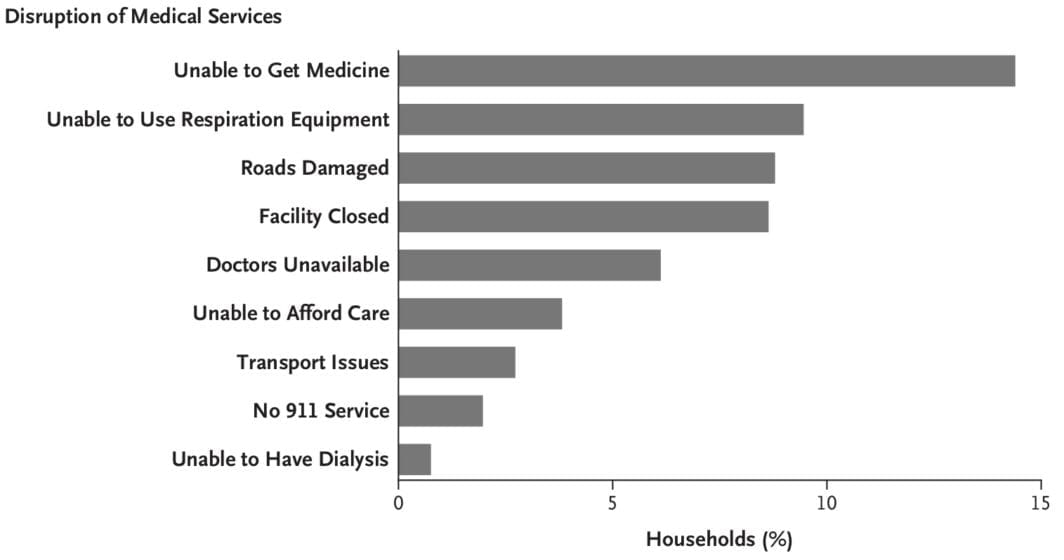
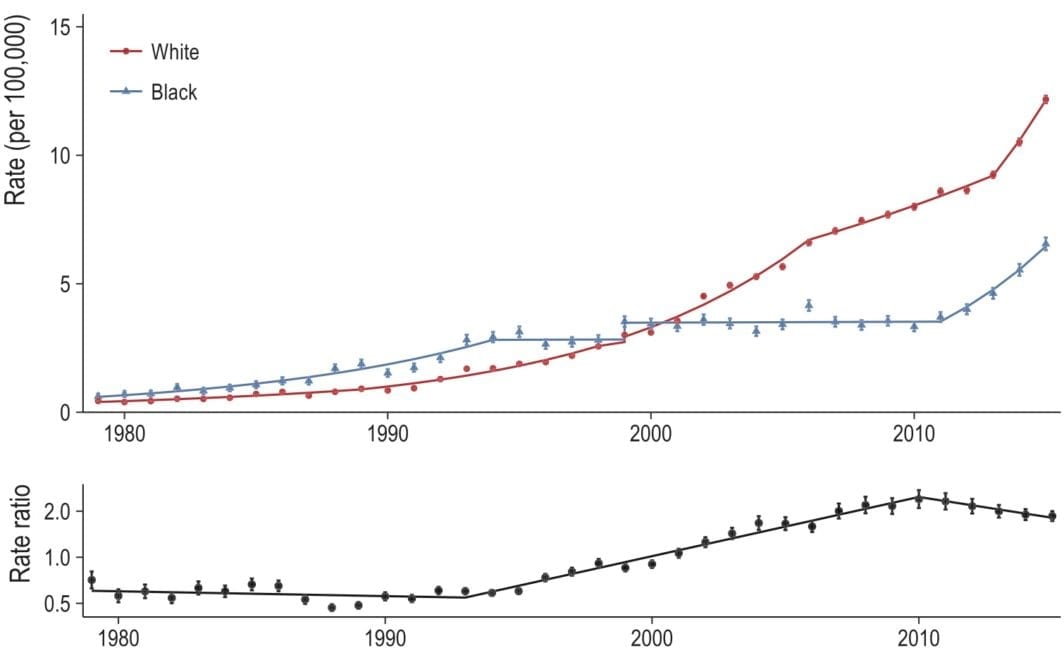
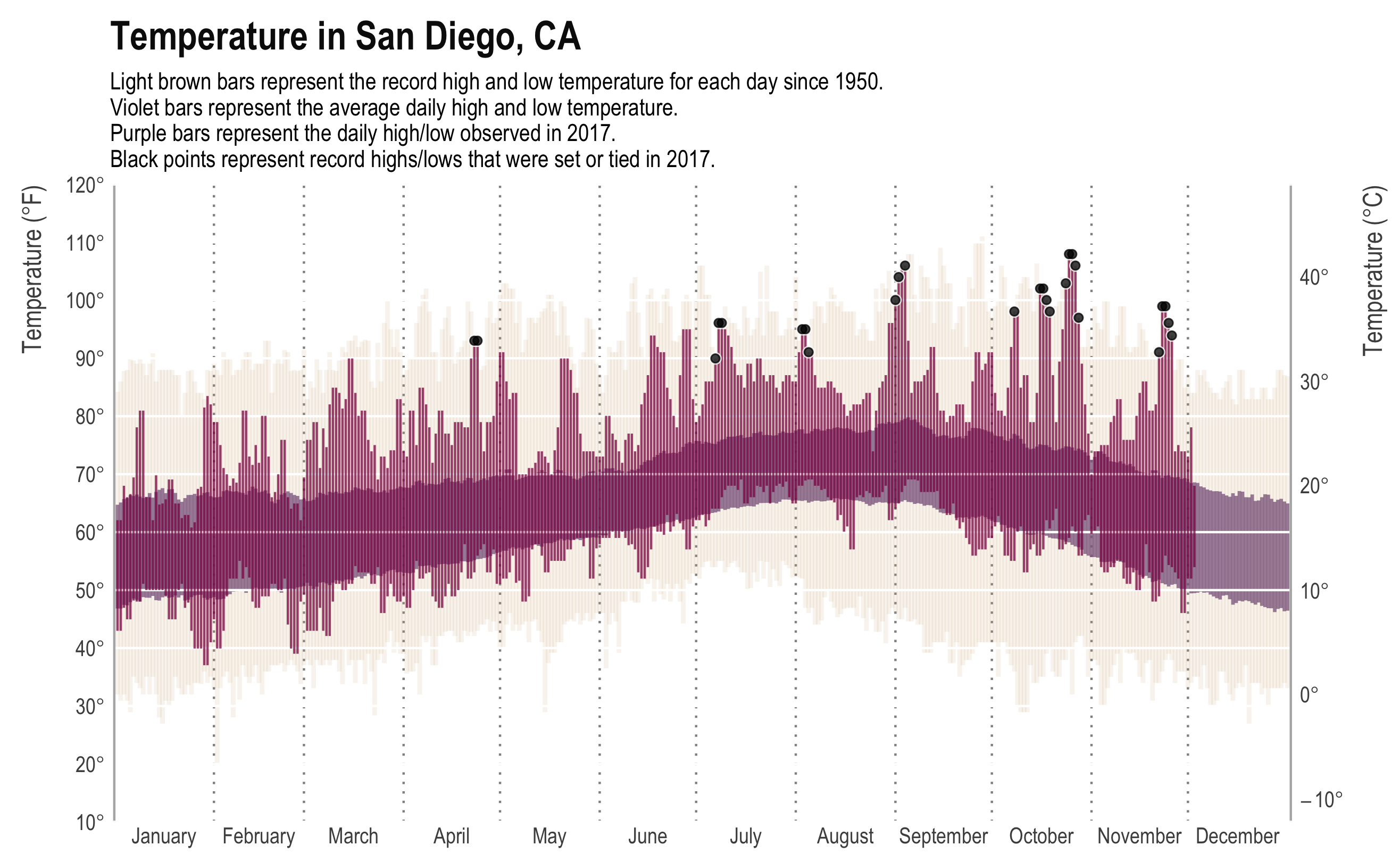
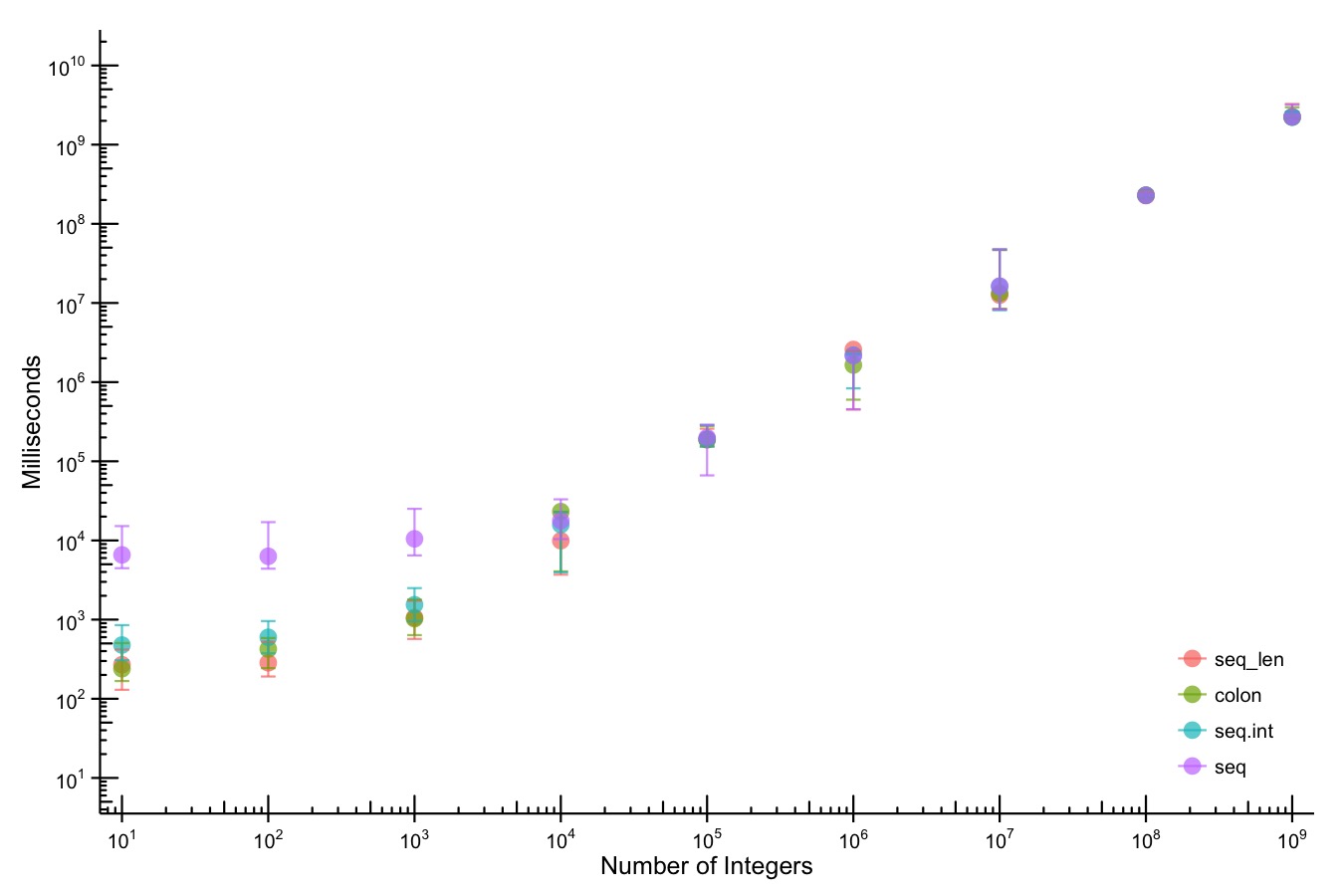
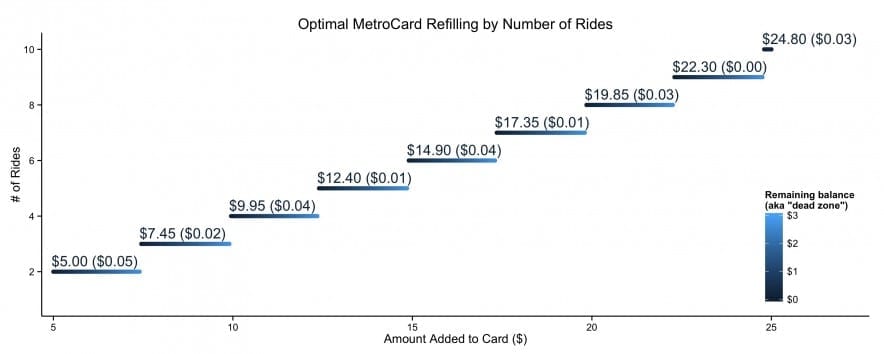
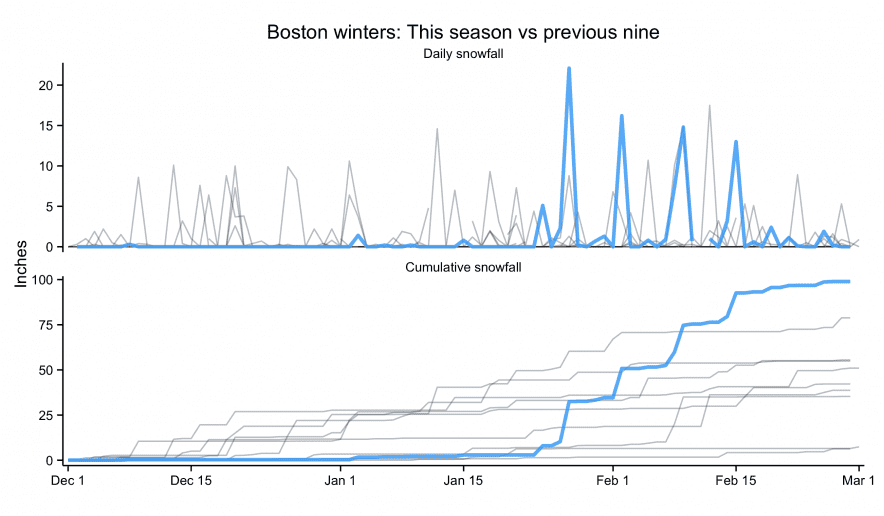
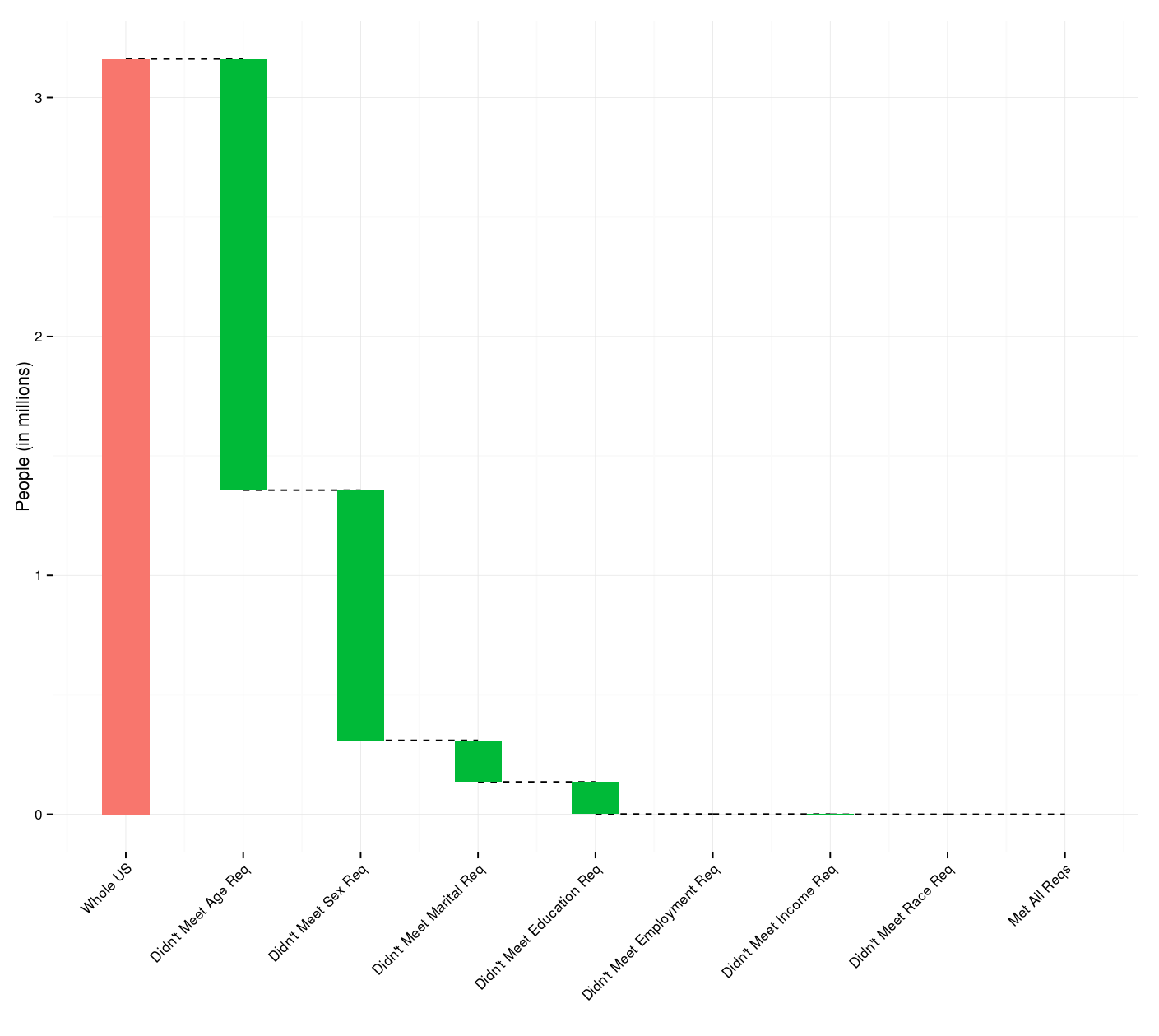
- In January (2025), I was on an NIH study section that got cancelled as the new administration shook up HHS/CDC/NIH and did some mass grant cancellations. It eventually got rescheduled but I wasn’t able to attend — I can only assume it was as hectic as one would imagine.
- Then in April, I was excited to start working on my second NASEM consensus committee. It got abruptly cancelled by the CDC the morning of our first meeting. This was, notably, after the whole committee was flown in from across the country the night before so couldn’t possibly have been a cost saving measure. We were never given a reason for the cancellation but I can only assume genetic blood disorders are woke.
- Then in October, I was on another NIH study section that got cancelled — this time due to the government shutdown. It’s scheduled for later this month, but as a result of the condensed timeline, we’re reviewing ~40% fewer grants than we would normally discuss in study section.
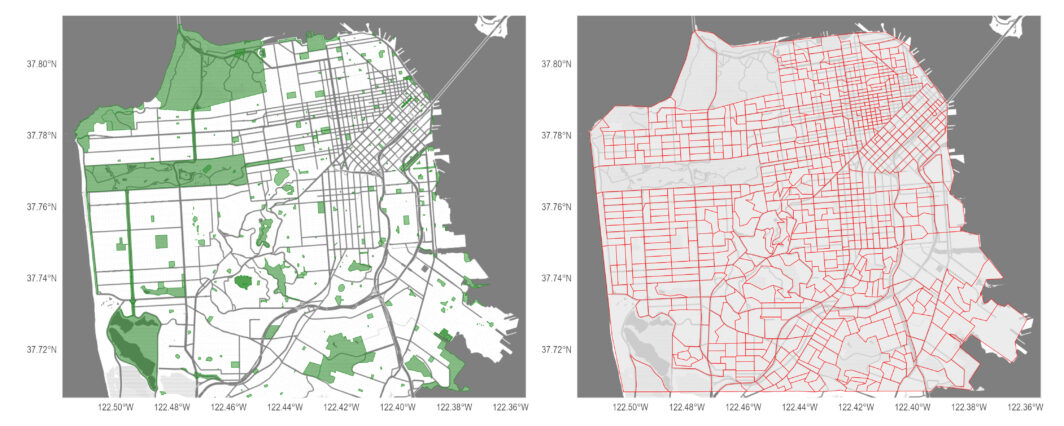
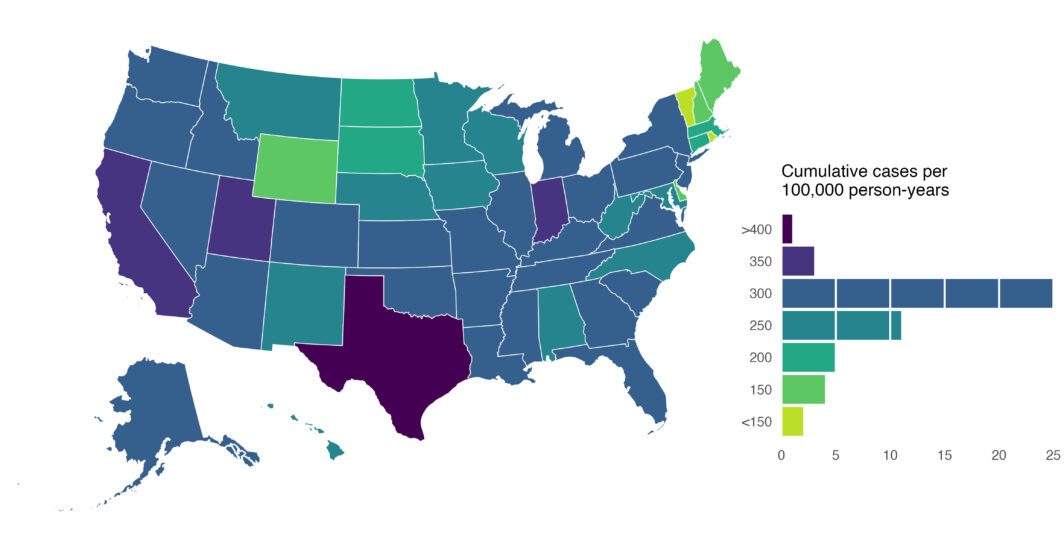
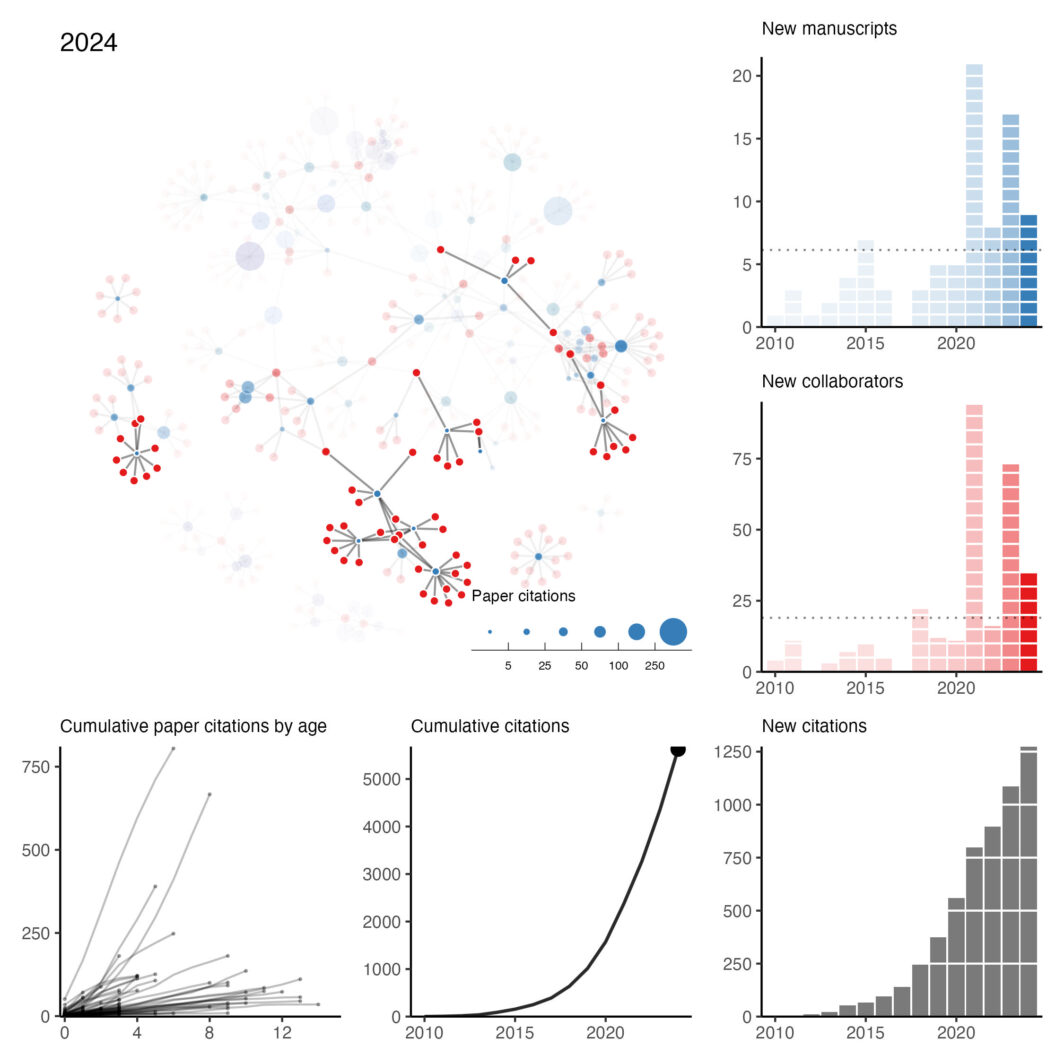
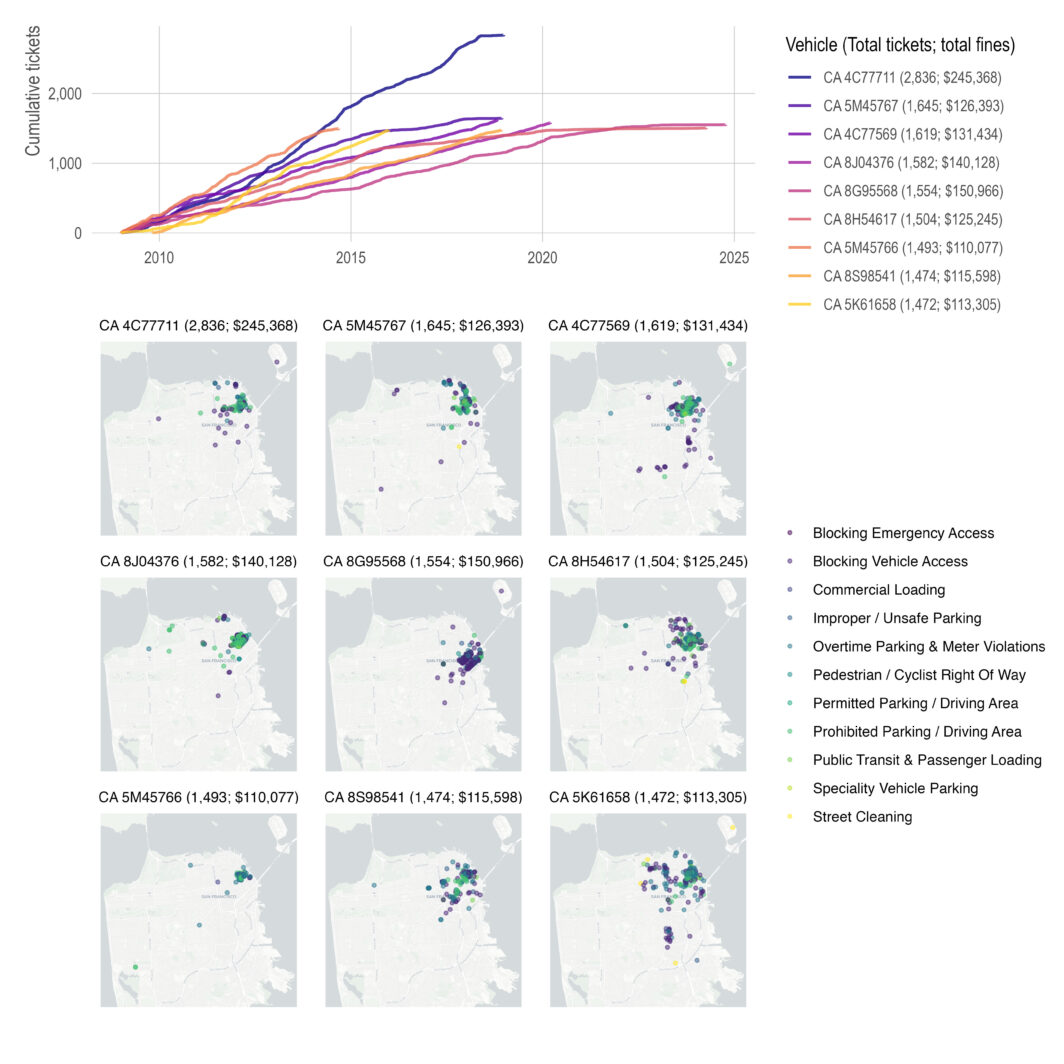
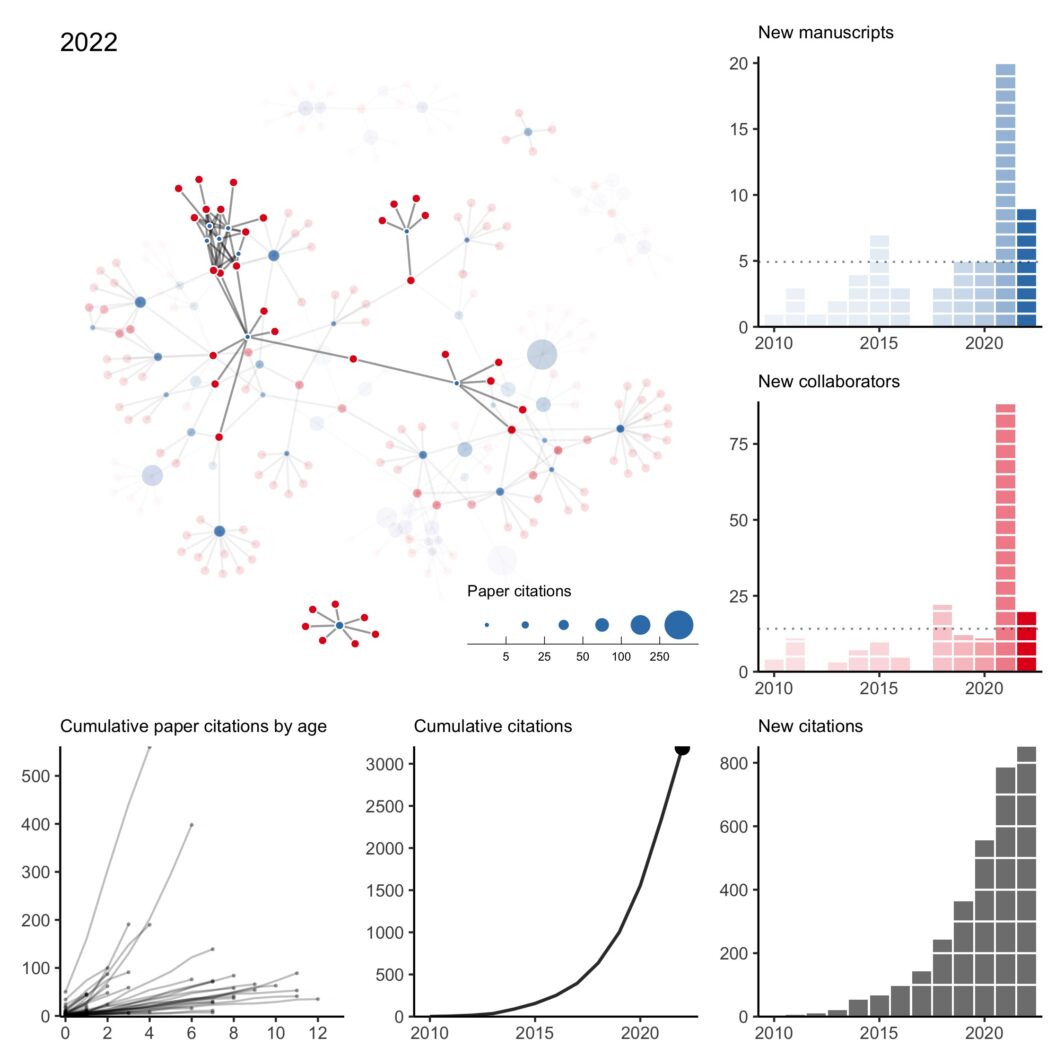
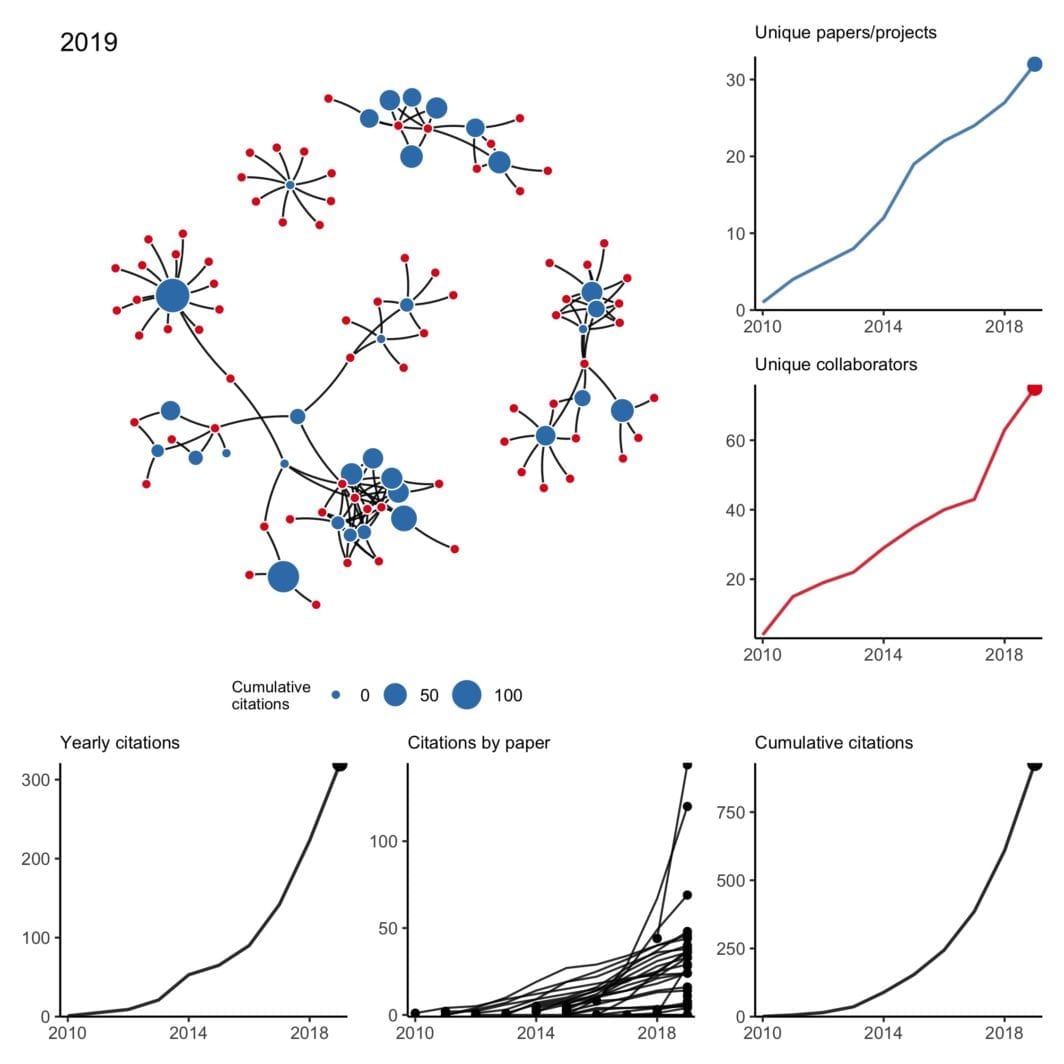
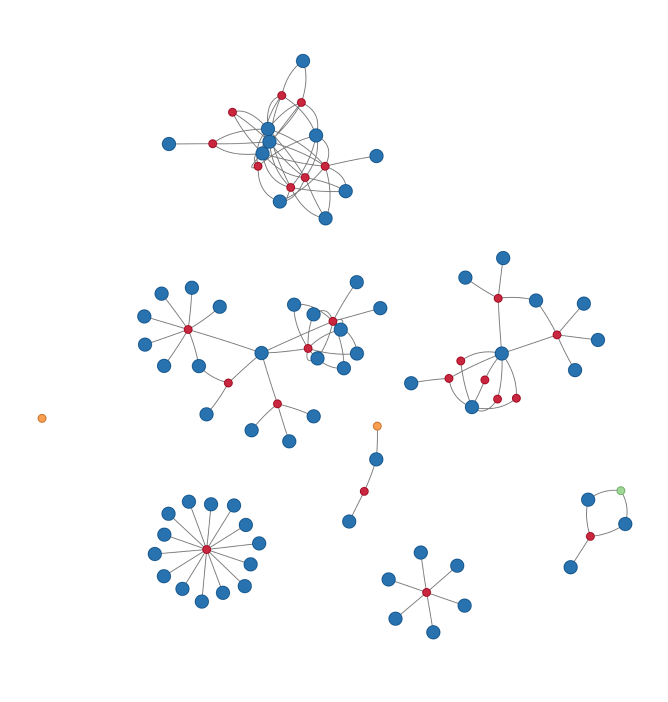
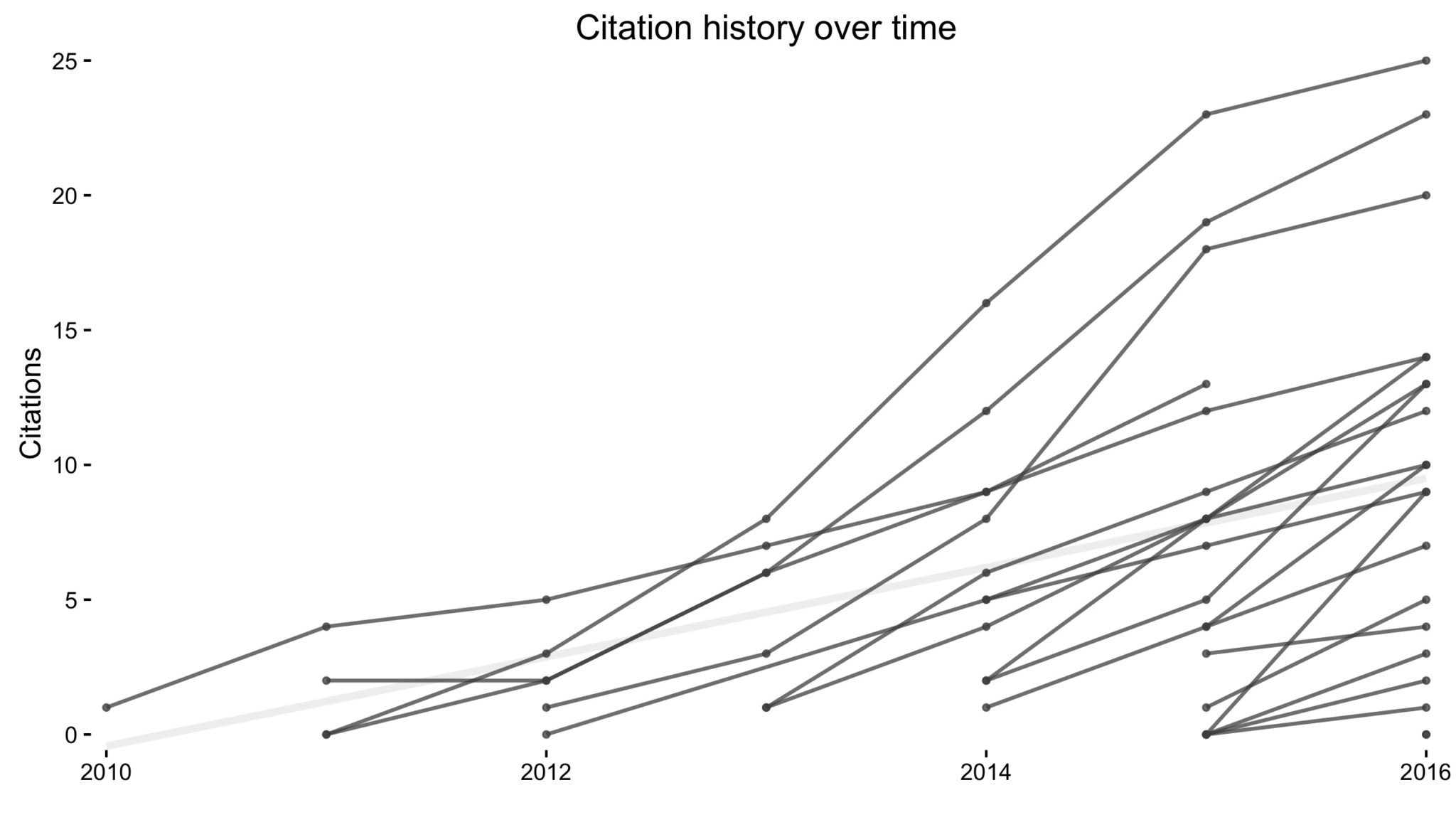
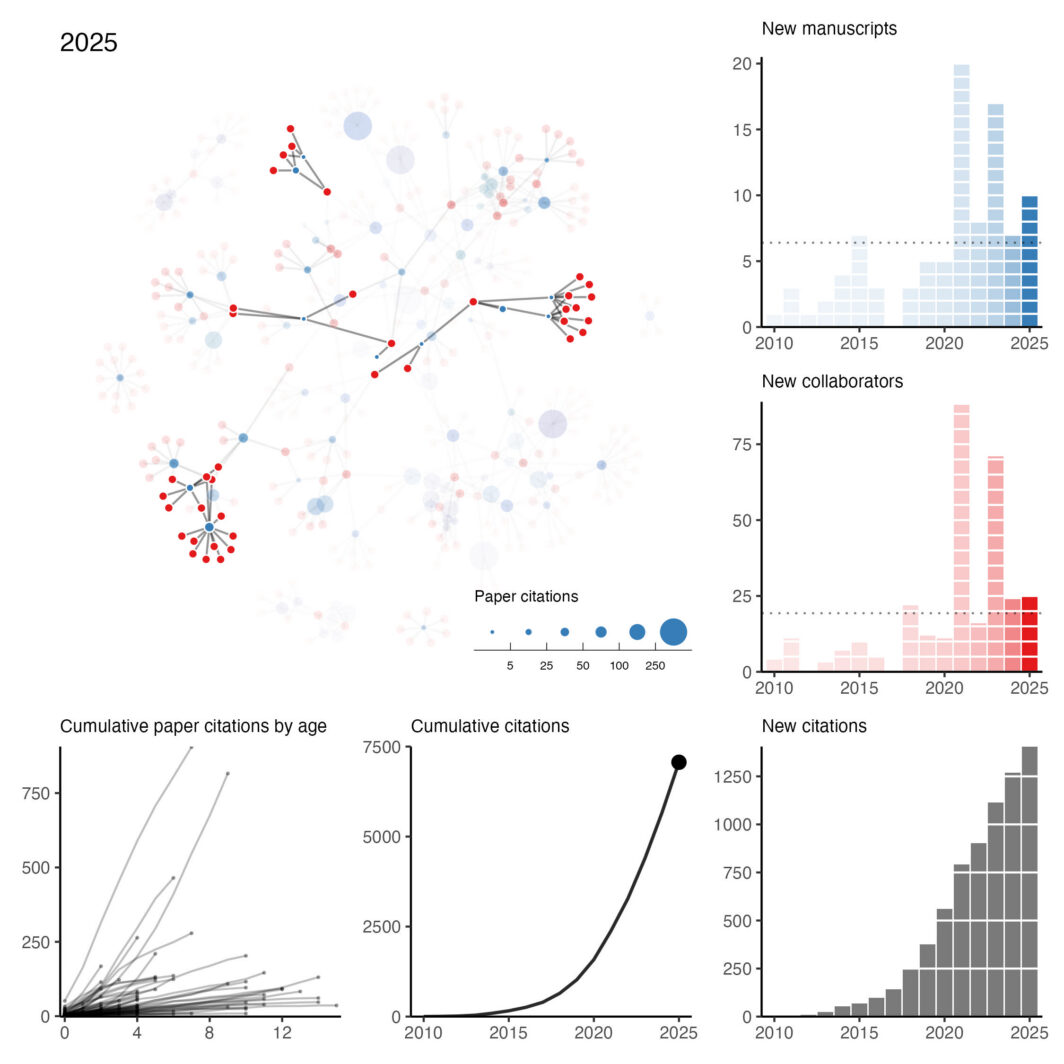
Collaboration network: 2025 edition
Looking back on what I think can be fairly described as a chaotic year (professionally), three events really encapsulated what it was like being in academia.