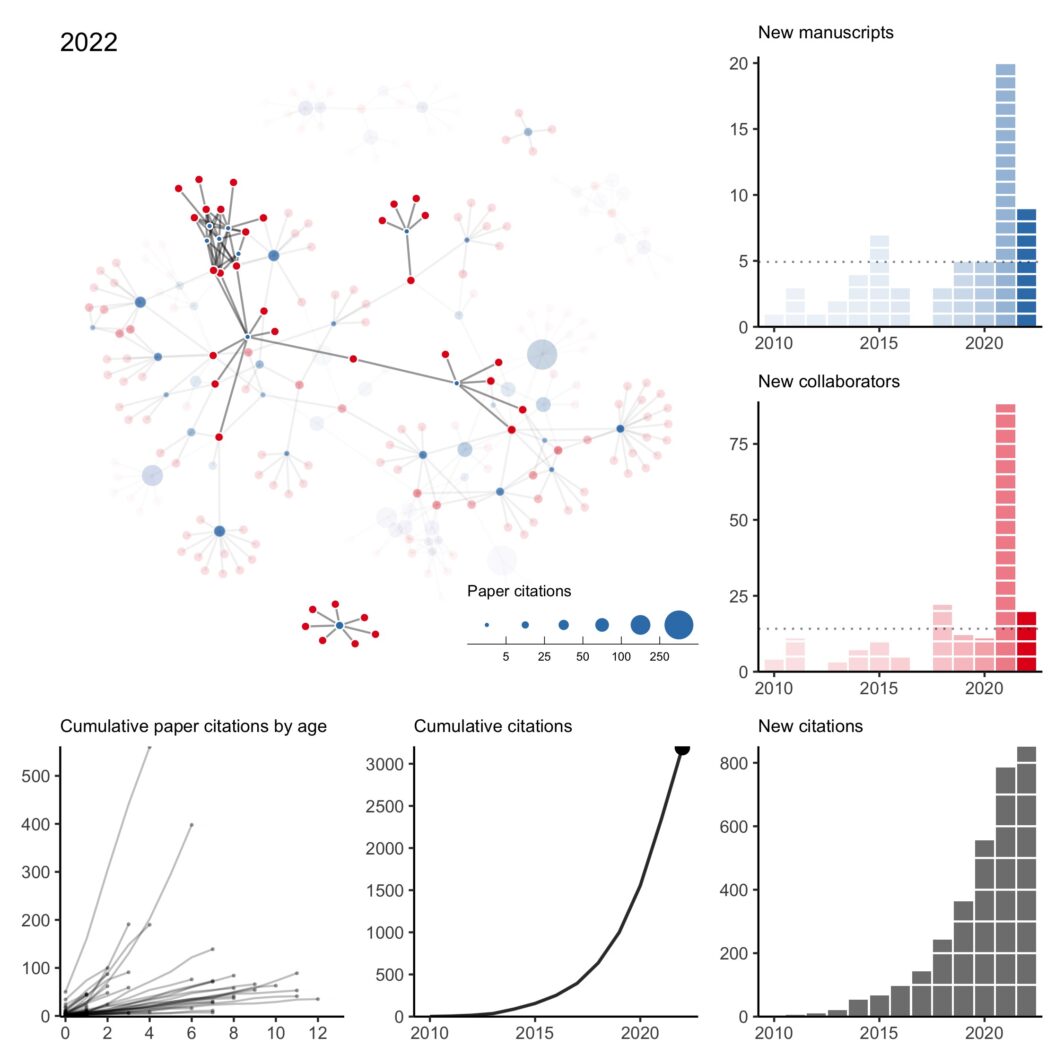
here was a lot going on last year and I missed my annual tradition of updating my collaboration network at the end of the year. However, thanks to a perpetual illness ravaging the house, I’ve found some sleepless hours to fix my old code and pick up the tradition again. As is always the case when I do this exercise, I can’t help but reflect back on 2022 (and 2021) with gratitude and appreciation for my amazing collaborators. It was my first year on the tenure-track and hours that normally would have been spent pushing research forward were instead spent …
Plots of my biking in 2022
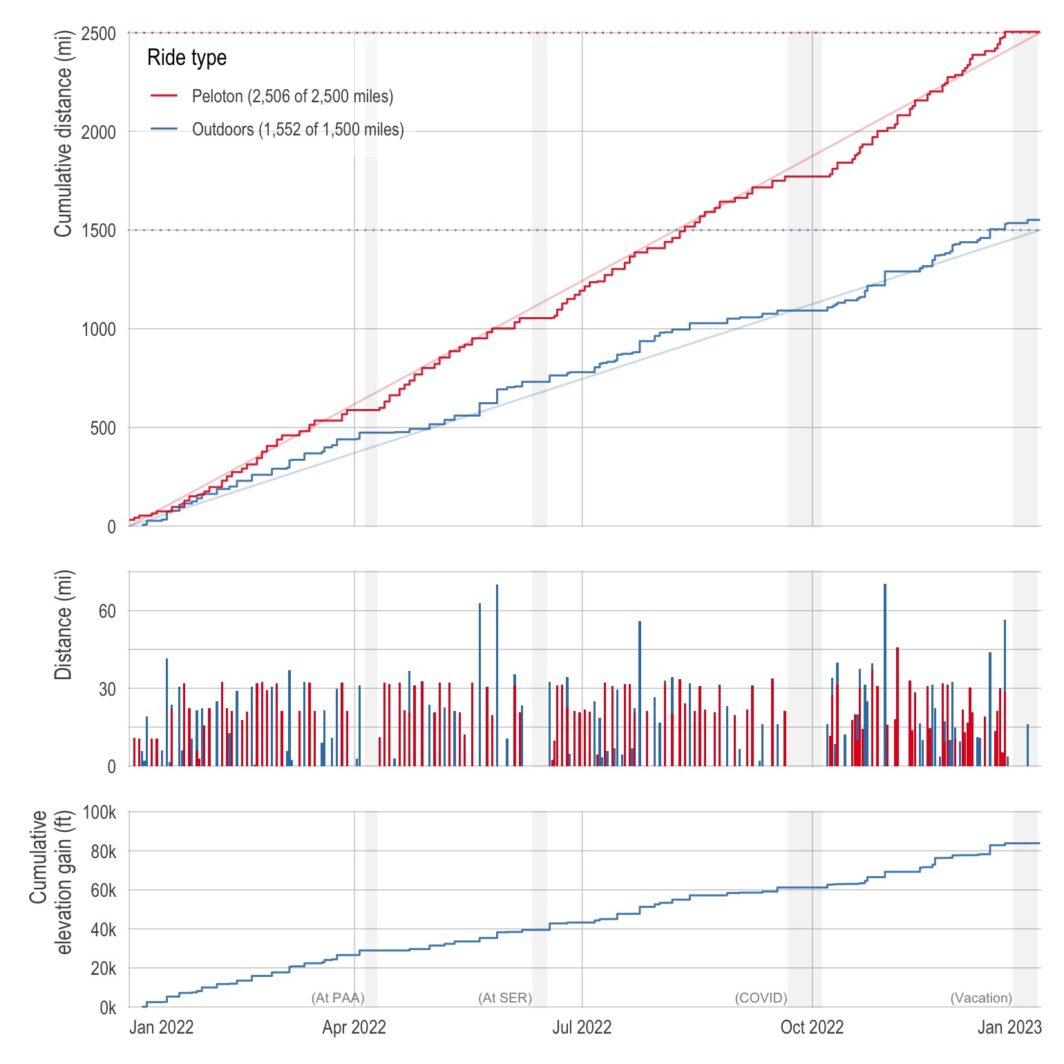
ne of the best things about living in California is having amazing weather nearly all year long (the current 3-week-stretch-of-non-stop-rain aside). So last year, I decided to capitalize on the weather and made a New Year’s resolution to bike outdoors more. Specifically, I wanted to bike 1,500 miles outdoors in addition to my normal indoor biking of 2,500 miles. (Also, with a side quest of 100,000 feet of cumulative elevation gain.) Below is a plot of my cumulative distance (and elevation) over the course of the year. I just barely got the distance resolutions with 1,551.7 miles outdoors and 2,506.1 …
It finally happened — I got COVID
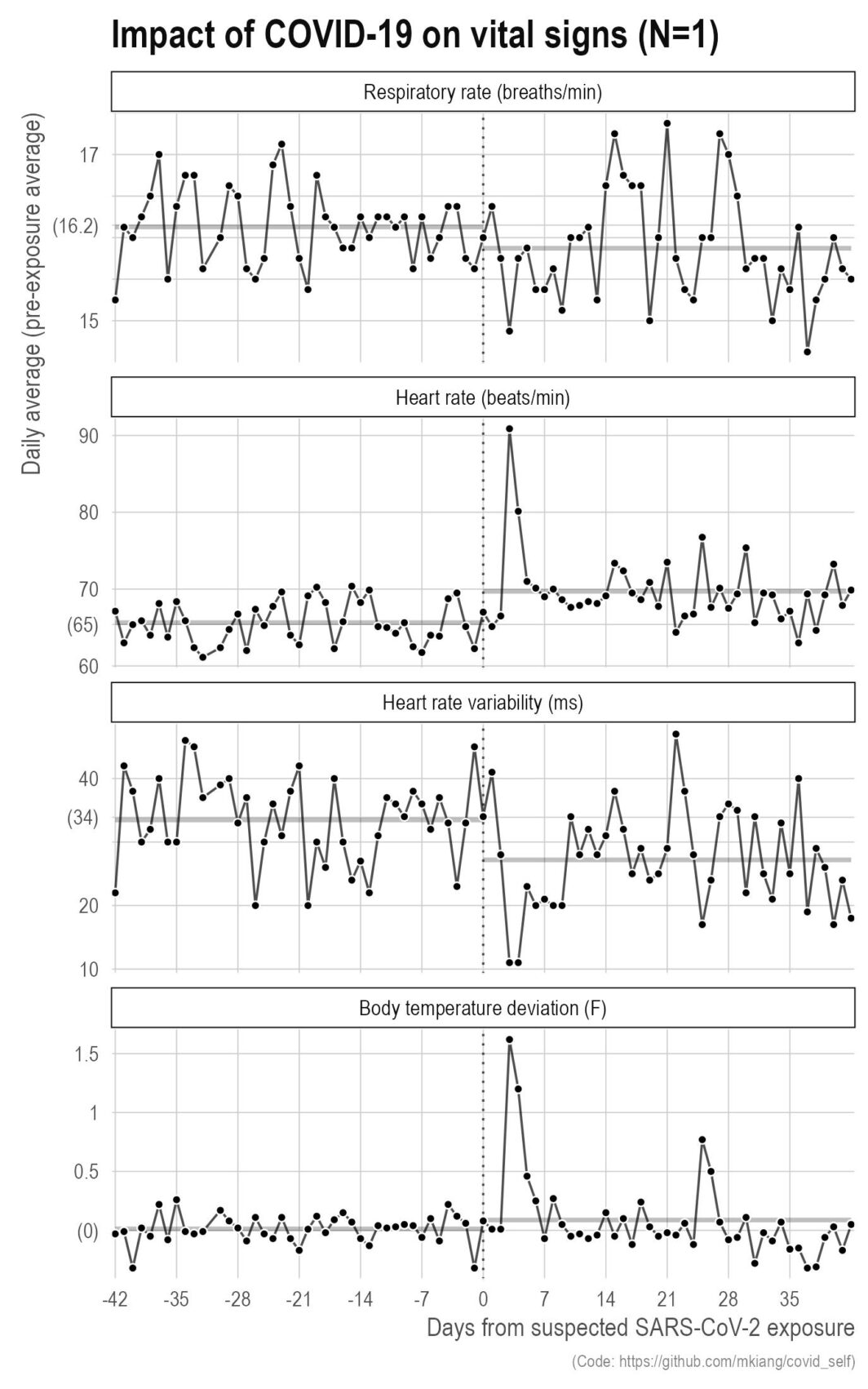
ast September, I got COVID. It was wildly unpleasant with serious brain fog that lasted for several weeks even after the other symptoms went away. That said, this did give me the opportunity to make some more plots based on my own data. Below, I show a few metrics of my vital signs (respiratory rate, heart rate, heart rate variability, and body temperature deviation) relative to my exposure (vertical dotted line) for six weeks before and after. The thicker grey lines in the background are the pre- and post-exposure averages for those six weeks.
My collaboration network for 2010 to 2020 (+ other plots)
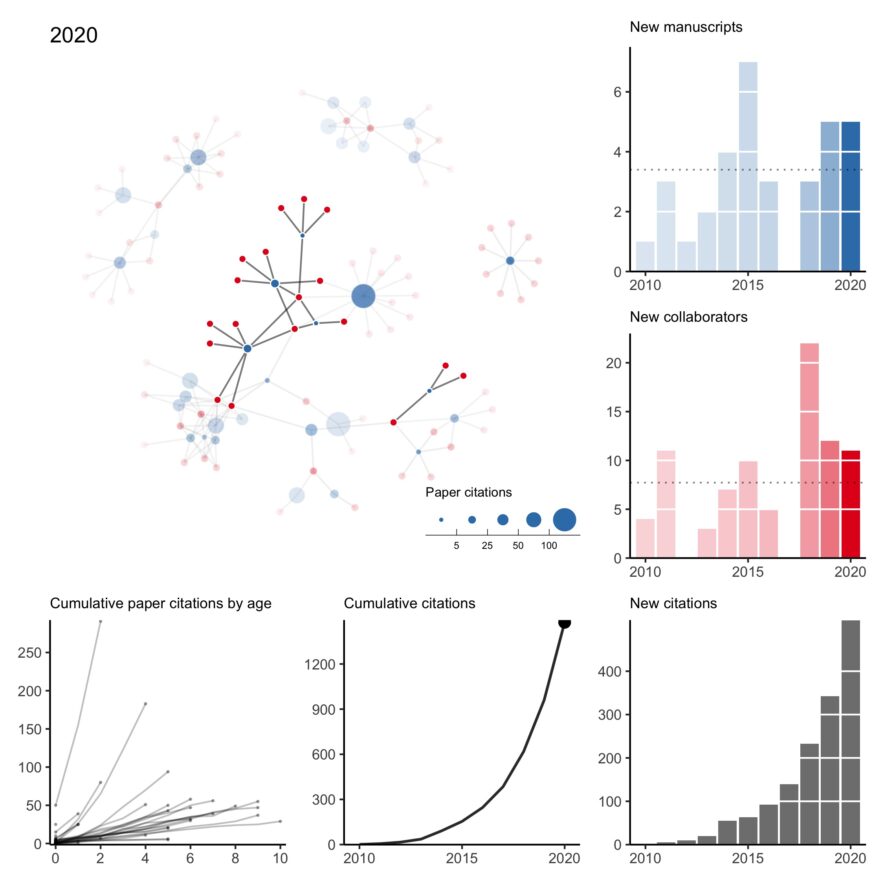
n what has become a bit of an annual tradition, here is my collaboration network for 2010 to 2020. This year was rough. Of the two first-author papers published this year, one was pre-pandemic. I think it’s fair to say this wasn’t the level of productivity I was expecting of myself. Hopefully, a few projects still in the pipeline will come out early next year. All that said, I’m thankful for a strong network of kind collaborators who picked up my slack when necessary, checked in on me even when we didn’t have an active project, and understood when childcare …
Applying an intro-level networks concept to deleting tweets
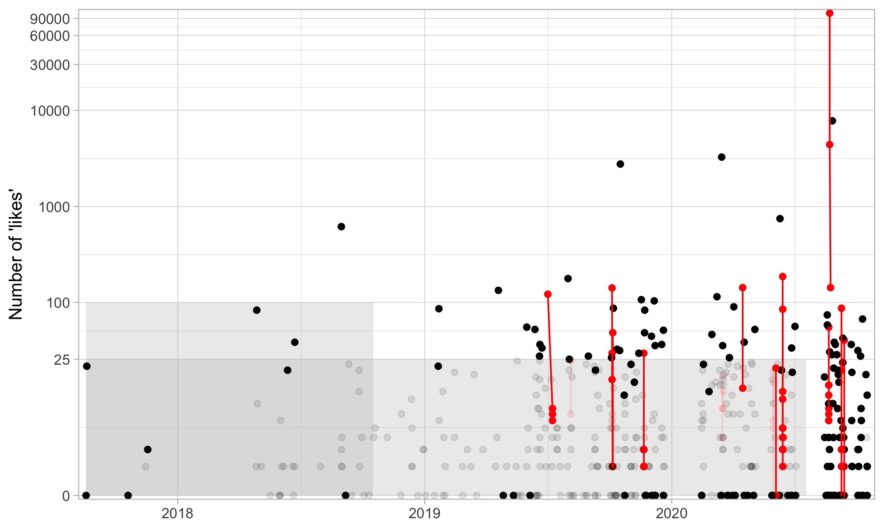
here are a few services out there that will delete your old tweets for you, but I wanted to delete tweets with a bit more control. For example, there are some tweets I need to keep up for whatever reason (e.g., I need it for verification) or a few jokes I’m proud of and don’t want to delete. If you just want the R code to delete some tweets based on age and likes, here it is (noting that it is based on Chris Albon’s Python script). In this post, I go over a bit of code about what I …
Our new paper about opioid prescribing patterns in the US
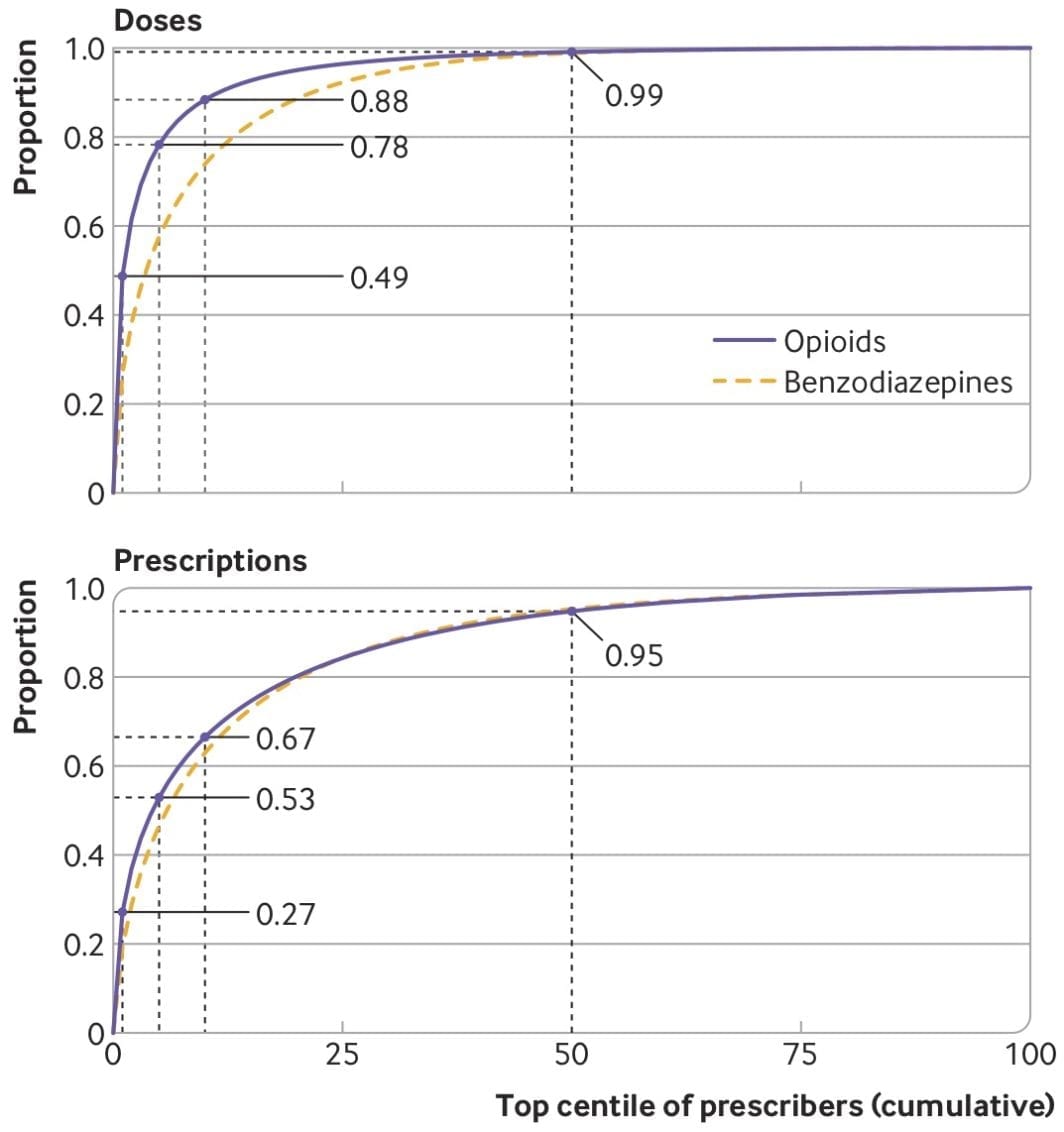
ome notes about a new (open access) paper with Keith Humphreys, Mark Cullen, and Sanjay Basu — “Opioid prescribing patterns among medical providers in the United States, 2003-17: retrospective, observational study” — just published in BMJ.
Collaboration network from 2010 to 2019
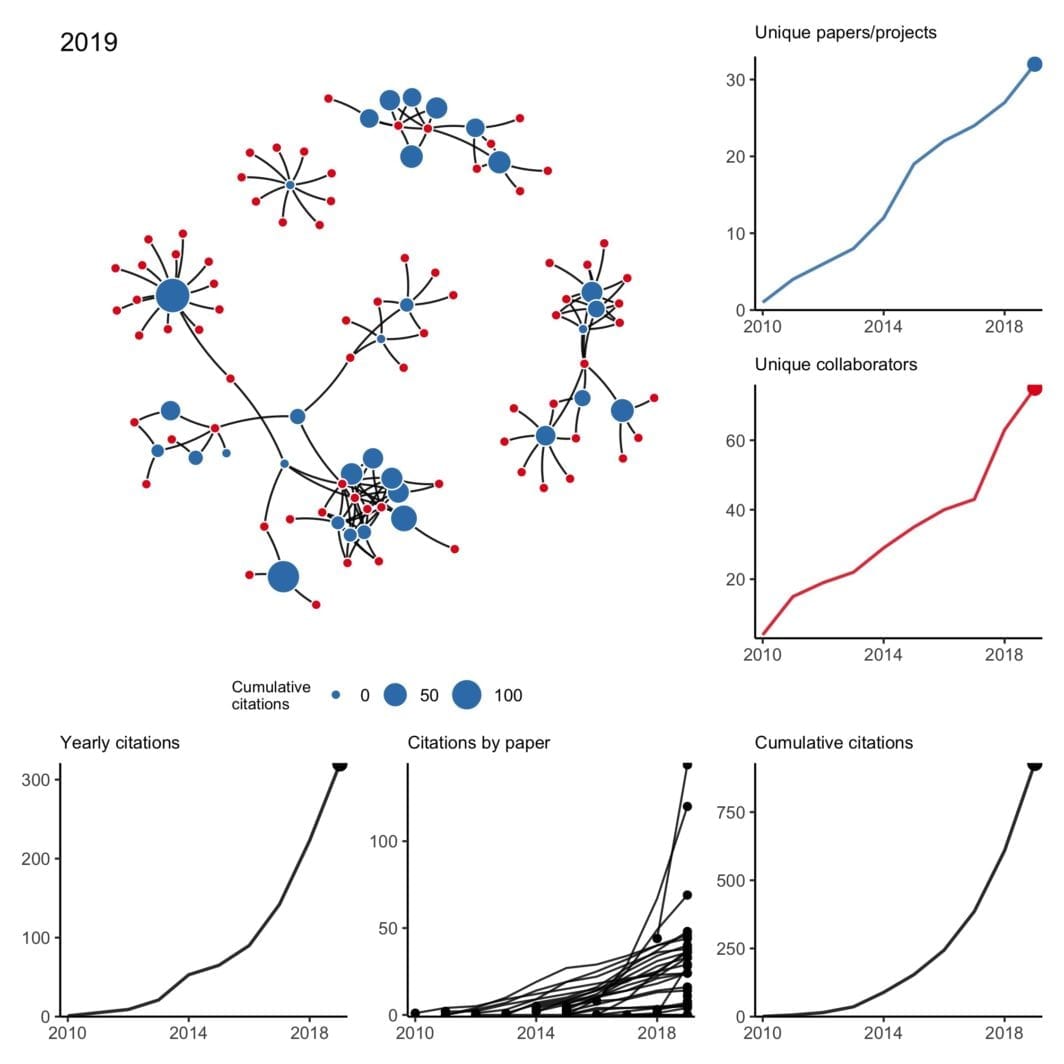
have been trying to wrap my head around working with temporal networks — not just simple edge activation that changes over time but also evolving node attributes and nodes that may appear and disappear at random. What better way than to work with a small concrete example I’m already very familiar with?
A visual tour of my publications
recently came across this paper by Michal Brzezinski about (the lack of) power laws in citation distributions. It made me a little curious about the citations of my own articles so I threw together a little script using James Keirstead’s Scholar package for R. In the plot above, every line represents a single article with time on the x-axis and (cumulative) number of citations on the y-axis. It’s not super informative, so we can break it down a few ways to graphically explore the data.